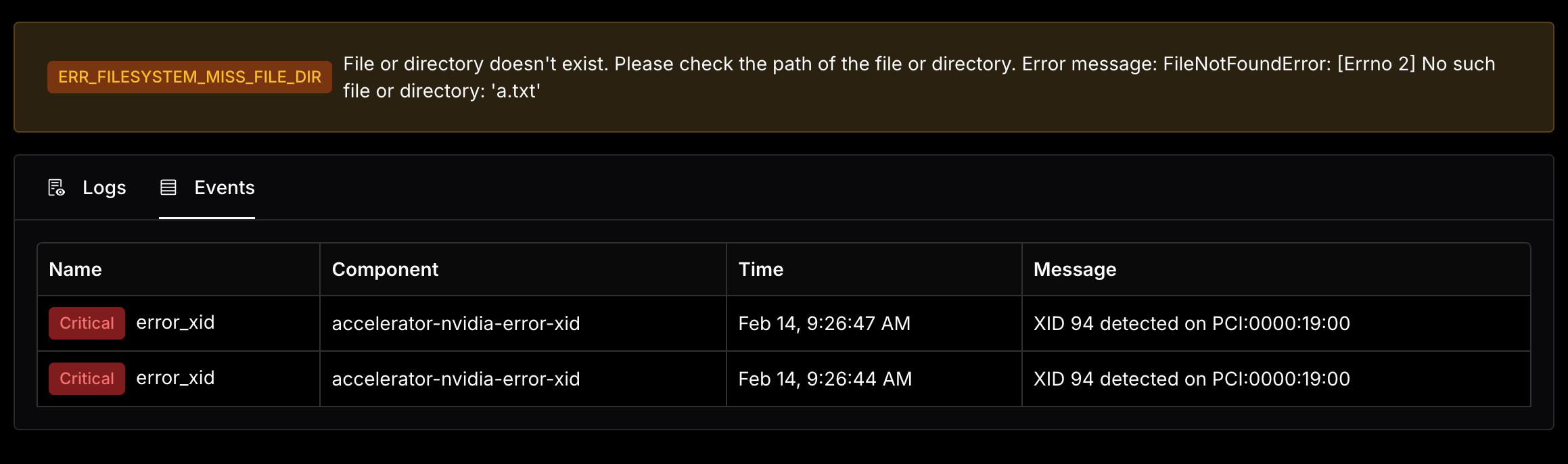
Logs
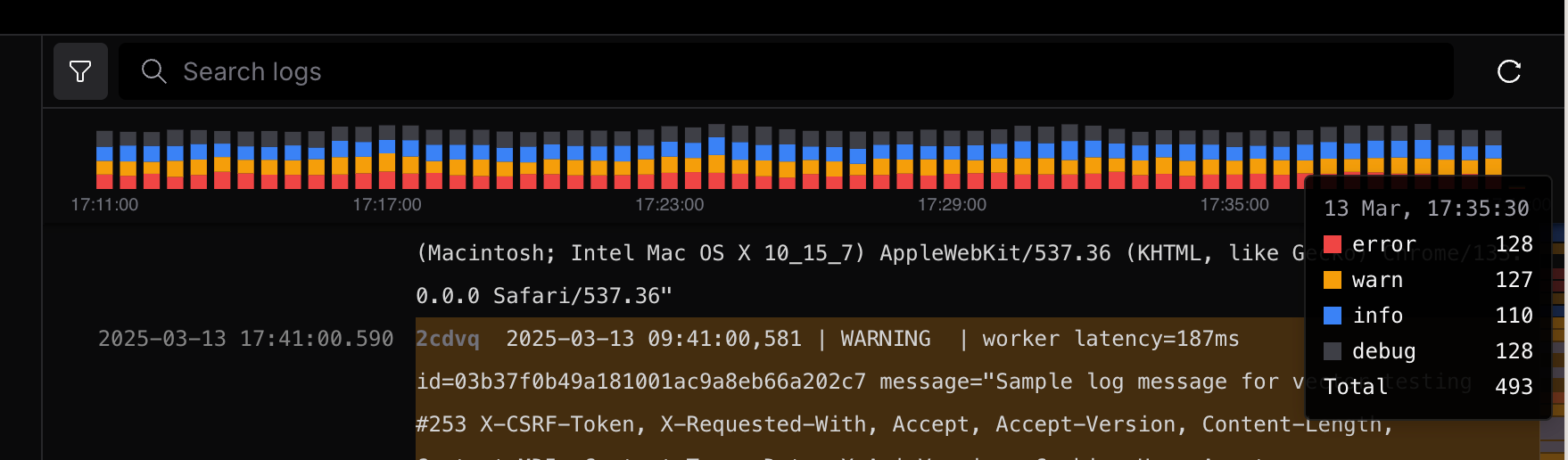
- Introduced a level filter for logs, enabling users to filter logs by level including
Debug,Warn, andError.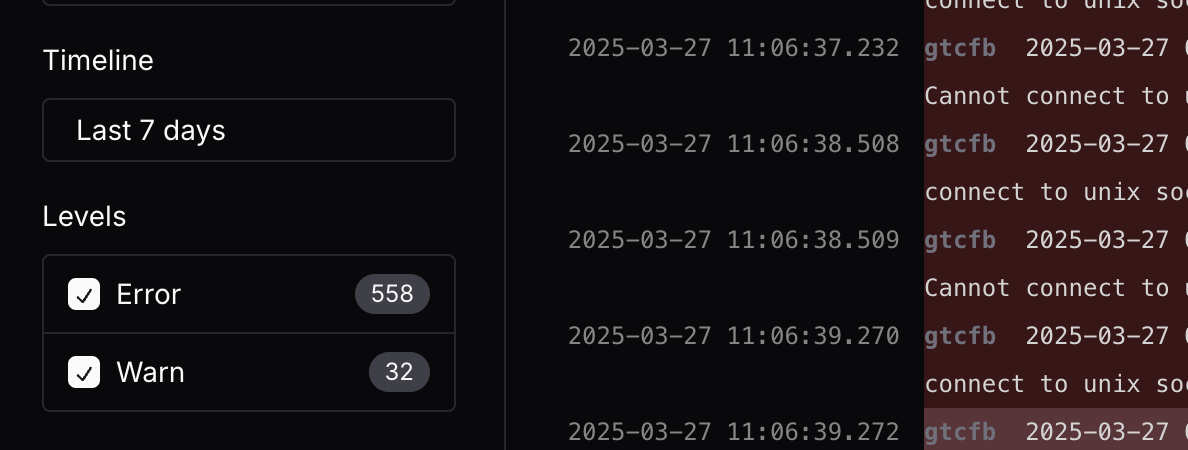
- Optimized logs experience by normalizing the log format for better readability and enhancing the logs style.
Node Group
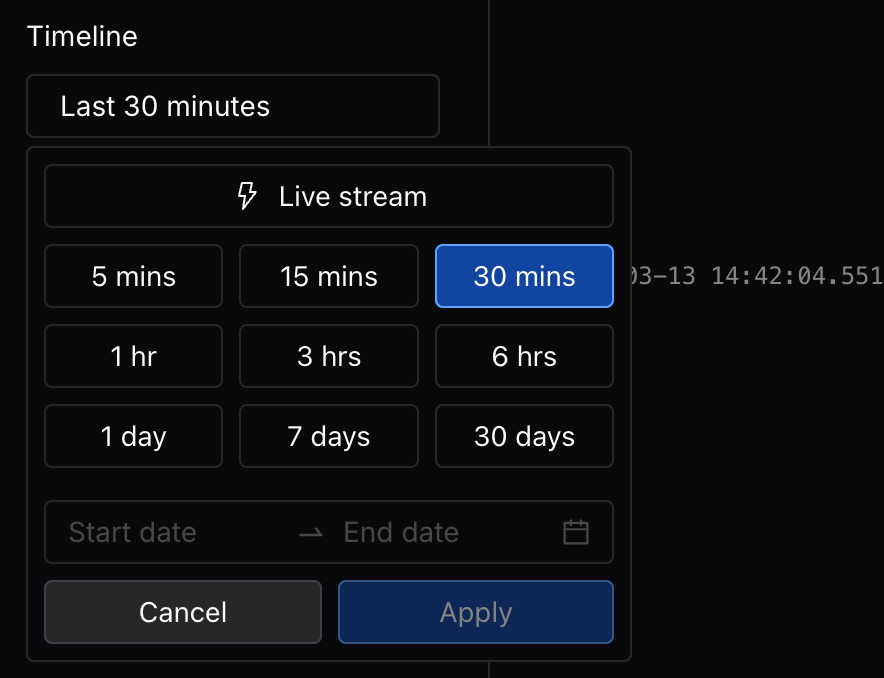
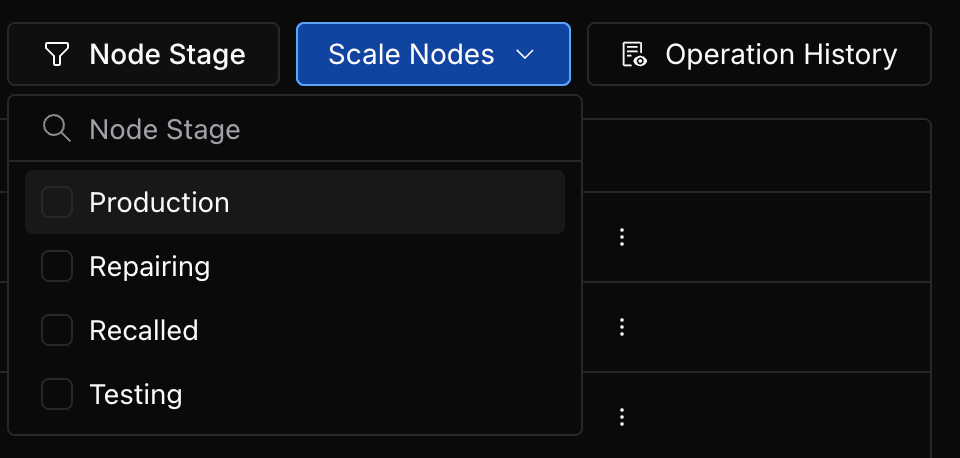
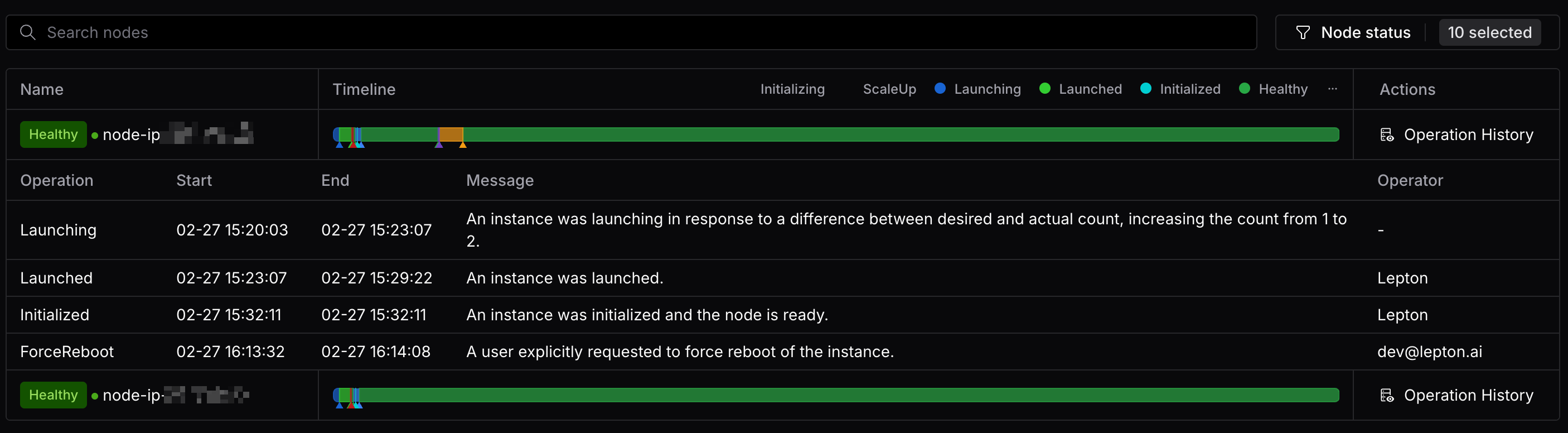
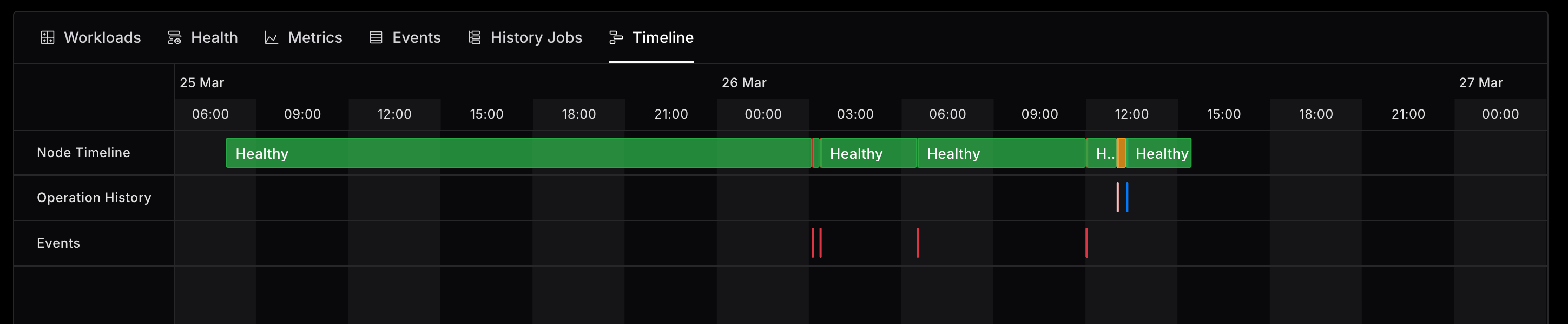
- Added interactive timeline chart for nodes, enabling users to inspect nodes' state changes, review its operation history and track critical events occurred on the node.
Workspace
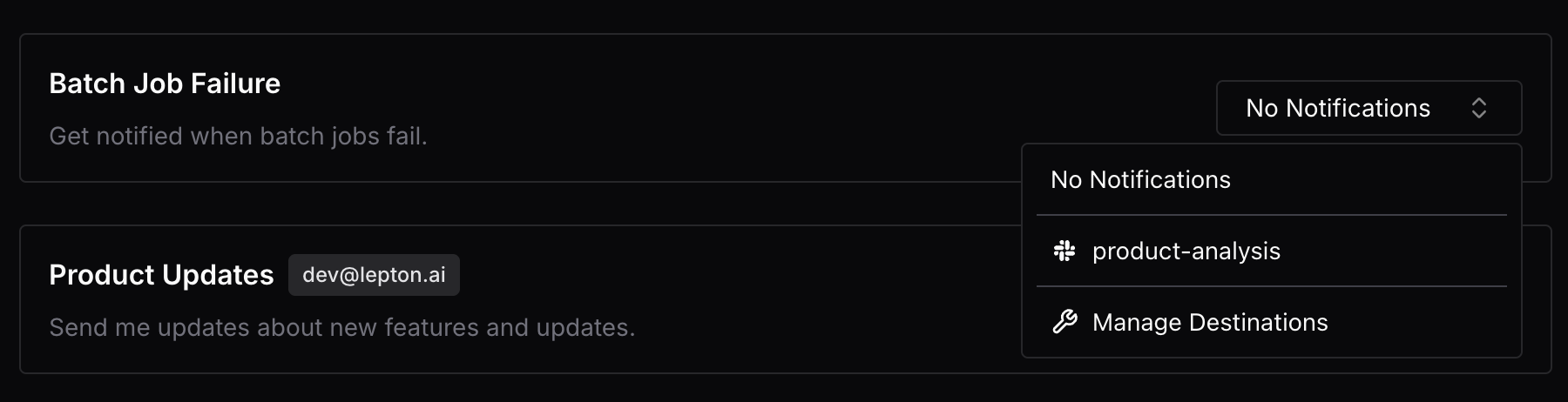
- Introduced failed job alert feature, supporting send alerts when failed jobs are detected to slack channels via webhooks.